Microphone Conversion: Mitigating Device Variability in Sound Event Classification
[ICASSP 2024] A generative method to tackle domain mismatch problem in sound event classifcation systems
In this post, I am going to introduce our work accepted to 2024 IEEE ICASSP. You can access the full paper here.
Exploring the World of Sound Recognition
Sound Event Classification and the Challenge of Device Variability
Sound Event Classification (SEC) is a fascinating area of technology that aims to identify different types of sounds, like speech, music, and environmental noises, using advanced signal processing and machine learning techniques. Sound Event Classification (SEC) powers popular technologies like Apple’s Sound Recognition, Amazon’s Alexa, and Google Home, enabling them to identify sounds from speech to environmental noises. Despite its broad applications, SEC faces challenges, particularly when audio is recorded on different devices, leading to performance issues. These variations, often imperceptible to human ears, can drastically affect the performance of SEC systems.
Our Innovative Approach to Enhance Reliability
Traditional solutions, such as data augmentation, have been limited, often relying on synthetic data which doesn’t fully capture real-world complexities. Furthermore, most initiatives, including those like the DCASE Challenge, have their limitations, primarily due to their reliance on synthetic evaluation data. This limitation raises questions about the thoroughness and real-world applicability of their evaluations. Recognizing these challenges, our research addresses these challenges, aiming to enhance SEC systems for more accurate and reliable use in everyday technologies.
Developing a New Technique and Dataset
How We Created a Unique Sound Dataset
In our journey to enhance sound event classification, we crafted the ‘Deeply Device Dataset,’ a diverse collection capturing 75 sound classes. This dataset, a mix of direct recordings and recordings of the playback of anechoics samples from the RWCP Sound Scene Database, includes a variety of sounds from daily life noises and human interactions to musical instruments. Key to our approach was the use of 18 different recording devices, encompassing a range of smartphones, laptops, and specialized microphones, each adding its unique acoustic signature to the dataset.
The recording process unfolded in an anechoic chamber, an environment meticulously designed to eliminate external noise and echo, ensuring pristine audio capture. This setup allowed us to systematically record each sound class, with devices positioned to optimally capture the emitted sounds. The result is two subsets: a comprehensive one with all sound classes and devices, and a smaller, focused subset. Each sound event in these subsets was aligned and annotated with precision, offering a rich resource for analyzing how different devices impact sound event classification.
A comprehensive list of classes is provided as follows:
- Directly-produced (25)
- Sound of things (11): cell phone alarm, cell phone vibrating, hair dryer, fan, dish clanking, typing keyboard,clicking mouse, pouring water, knock, rustling, impulse
- Human sound (7): speech_1 (‘help me’ in Korean), speech_2 (‘save me’ in Korean), coughing, clapping, finger snap, whistle, throat clearing
- Musical instrument (7): ukulele, guitar, tambourine, hand drum, castanets, triangle, hand cymbals
- RWCP-SSD (50)
- Class 1 (17): bank, bottle, bowl, candybwl, case, cherry, china, coffcan, colacan, cup, dice, magno, metal, pan, teak, trashbox, wood
- Class 2 (10): aircap, cap, clap, claps, file, pump, sandpp, saw, snap, sticks
- Class 3 (23): bells, book, buzzer, castanet, clock1, clock2, coffmill, coin, coins, cymbals, doorlock, dryer, horn, maracas, padlock, phone , pipong, ring, shaver, stapler, string, toy, whistle

Simplifying Our Method for Better Sound Recognition
In our pursuit to enhance sound event classification (SEC), we introduced ‘Microphone Conversion’. This innovative technique aims to bridge the gap between different recording devices by transforming the spectrograms from one device to mimic those of another. At the heart of this technique is a mapping function, designed to convert the spectrogram data from a source device ($X_A$) into a form that statistically resembles the target device ($X_B$).
To achieve this, we employed CycleGAN
The effectiveness of CycleGAN in our context lies in its dual-loss setup. The adversarial loss pushes the generators to produce outputs that are indistinguishable from the target domain, ensuring authenticity. Meanwhile, the cycle-consistency loss guarantees that the generated images, once reverse-mapped, closely resemble their original forms. This balance ensures that while the style of the spectrograms adapts to the target domain, their content remains intact.
\[\mathcal{L}_{adv}(F, D_B, X_A, X_B) = \\ \mathbb{E}_{X_A{\sim}p(x_a)}\left[{\log}(1-D_B(F(X_A)))\right] + \mathbb{E}_{X_B{\sim}p(x_b)}\left[{\log}D_B(X_B)\right]\] \[\mathcal{L}_{cycle}(F, G, X_A, X_B) = \mathbb{E}_{X_A{\sim}p(x_a)}[||{G(F(X_A)) - X_A}||_{1}] + \mathbb{E}_{X_B{\sim}p(x_b)}[||{F(G(X_B)) - X_B}||_{1}]\]For the network architecture, we adapted the CycleGAN implementation directly from the original author’s code. Our generator network consists of two up- and down-sampling layers, along with nine residual blocks with instance normalization, with the omission of the hyperbolic tangent layer. The discriminator, a 16x16 PatchGAN with instance normalization, was chosen for its effectiveness in minimizing blurriness and ensuring better convergence in the output.
Through this approach, we were able to effectively ‘translate’ audio data across devices, preserving the integrity of the sound events while adapting to the unique acoustic characteristics of various recording devices.
Experiments and Results
Comparative Analysis: Our Method vs. Traditional Approaches
In our research, we demonstrated how our proposed method can benefit SEC systems in the face of device variability. We also conducted a thorough examination of the leading methods from recent DCASE Challenges, which are designed to mitigate device variability in sound event classification (SEC) systems, and compare their results with ours. The experiments were conducted using audio samples recorded from 7 different recording devices: iPhone 14, Galaxy S22, iPad 7, Galaxy Tab A8, Apple Watch SE, Macbook Pro(’20), and LG Gram(’20).
We evaluated techniques like Freq-MixStyle
| Method | S | T1 | T2 | T3 | T4 | T5 | T6 | Overall (- S) |
|---|---|---|---|---|---|---|---|---|
| Baseline | 0.982 | 0.409 | 0.709 | 0.248 | 0.471 | 0.687 | 0.491 | 0.503 ± 0.167 |
| Gaussian Noise | 0.983 | 0.708 | 0.918 | 0.576 | 0.565 | 0.780 | 0.683 | 0.705 ± 0.127 |
| Reverberation | 0.980 | 0.895 | 0.852 | 0.539 | 0.832 | 0.736 | 0.360 | 0.702 ± 0.202 |
| Pitch Shift | 0.981 | 0.471 | 0.744 | 0.221 | 0.658 | 0.648 | 0.442 | 0.531 ± 0.183 |
| SpecAugment | 0.985 | 0.372 | 0.762 | 0.214 | 0.363 | 0.634 | 0.324 | 0.445 ± 0.199 |
| MixUp | 0.983 | 0.336 | 0.677 | 0.213 | 0.449 | 0.656 | 0.387 | 0.453 ± 0.175 |
| FilterAugment | 0.981 | 0.964 | 0.891 | 0.586 | 0.874 | 0.794 | 0.642 | 0.792 ± 0.143 |
| Freq-MixStyle | 0.974 | 0.839 | 0.879 | 0.795 | 0.902 | 0.885 | 0.832 | 0.855 ± 0.038 |
| RFN | 0.980 | 0.919 | 0.909 | 0.742 | 0.907 | 0.829 | 0.614 | 0.820 ± 0.116 |
| MC-100-Gen | 0.981 | 0.958 | 0.912 | 0.894 | 0.899 | 0.831 | 0.852 | 0.891 ± 0.043 |
| MC-200-Gen | 0.982 | 0.969 | 0.909 | 0.903 | 0.912 | 0.859 | 0.887 | 0.907 ± 0.035 |
| MC-100-Adapt (p=0.5) | - | 0.956 | 0.905 | 0.904 | 0.880 | 0.902 | 0.890 | 0.906 ± 0.025 |
| MC-100-Adapt (p=1.0) | - | 0.891 | 0.906 | 0.855 | 0.834 | 0.811 | 0.808 | 0.851 ± 0.039 |
| MC-200-Adapt (p=0.5) | - | 0.965 | 0.922 | 0.906 | 0.910 | 0.908 | 0.907 | 0.920 ± 0.022 |
| MC-200-Adapt (p=1.0) | - | 0.935 | 0.917 | 0.864 | 0.873 | 0.880 | 0.848 | 0.886 ± 0.032 |
| Real | 0.983 | 0.982 | 0.972 | 0.985 | 0.979 | 0.983 | 0.986 | 0.981 ± 0.005 |
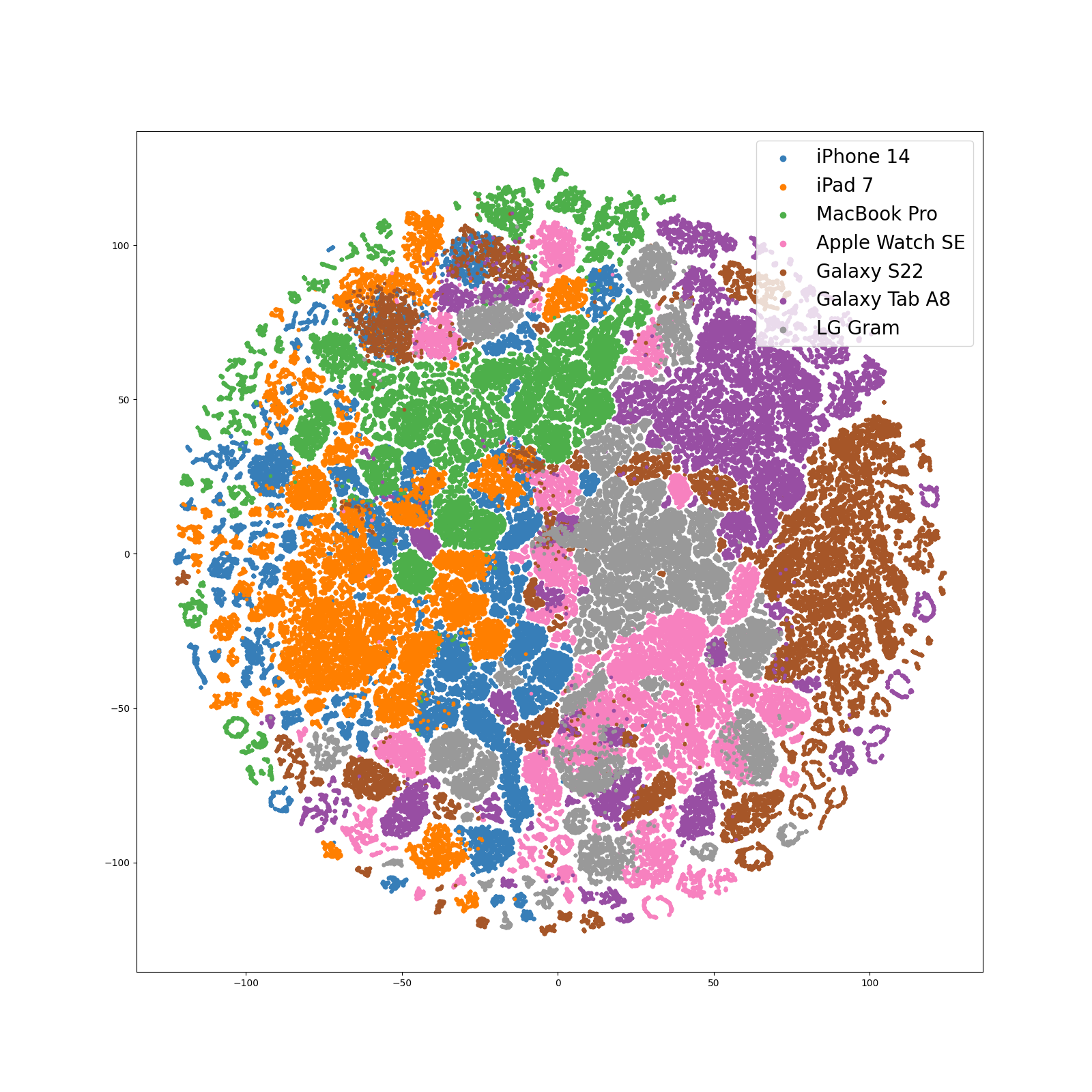
Our evaluation, as detailed in the above table, highlighted significant performance vulnerabilities in SEC systems when dealing with heterogeneous recording devices. A striking example was observed in the case of Galaxy Tab A8, where there was a dramatic performance drop of up to 73.7% compared to the baseline ‘Real’ metric, an ideal case where training and inference domain matches. Conversely, models showed better performance on devices like iPad 7 and Macbook Pro(’20), which share more similarities with the training data, as evidenced by their proximity in the t-SNE feature space, with a more modest performance drop of 26.3% and 29.5%, respectively. Traditional data augmentation methods offered limited improvement.
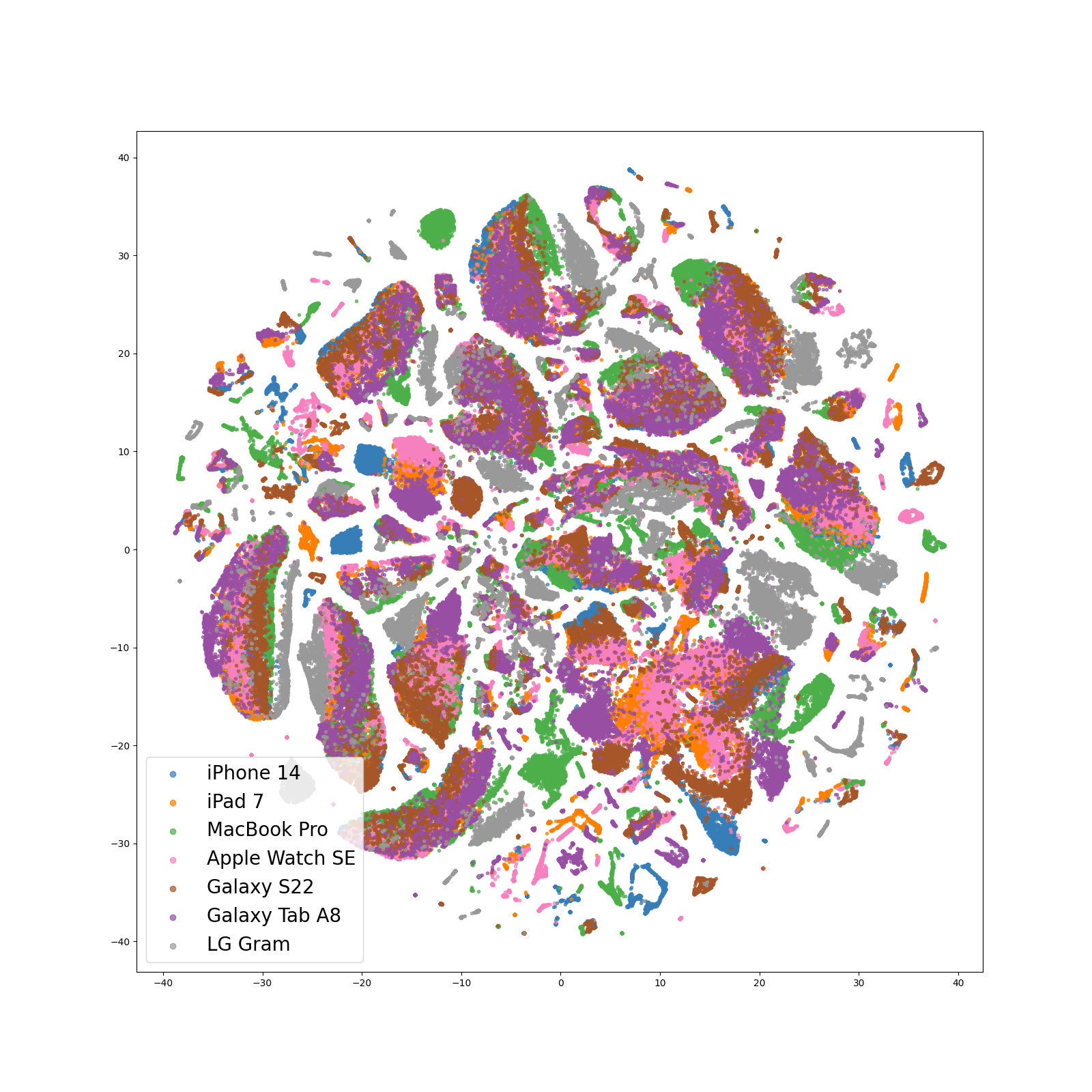
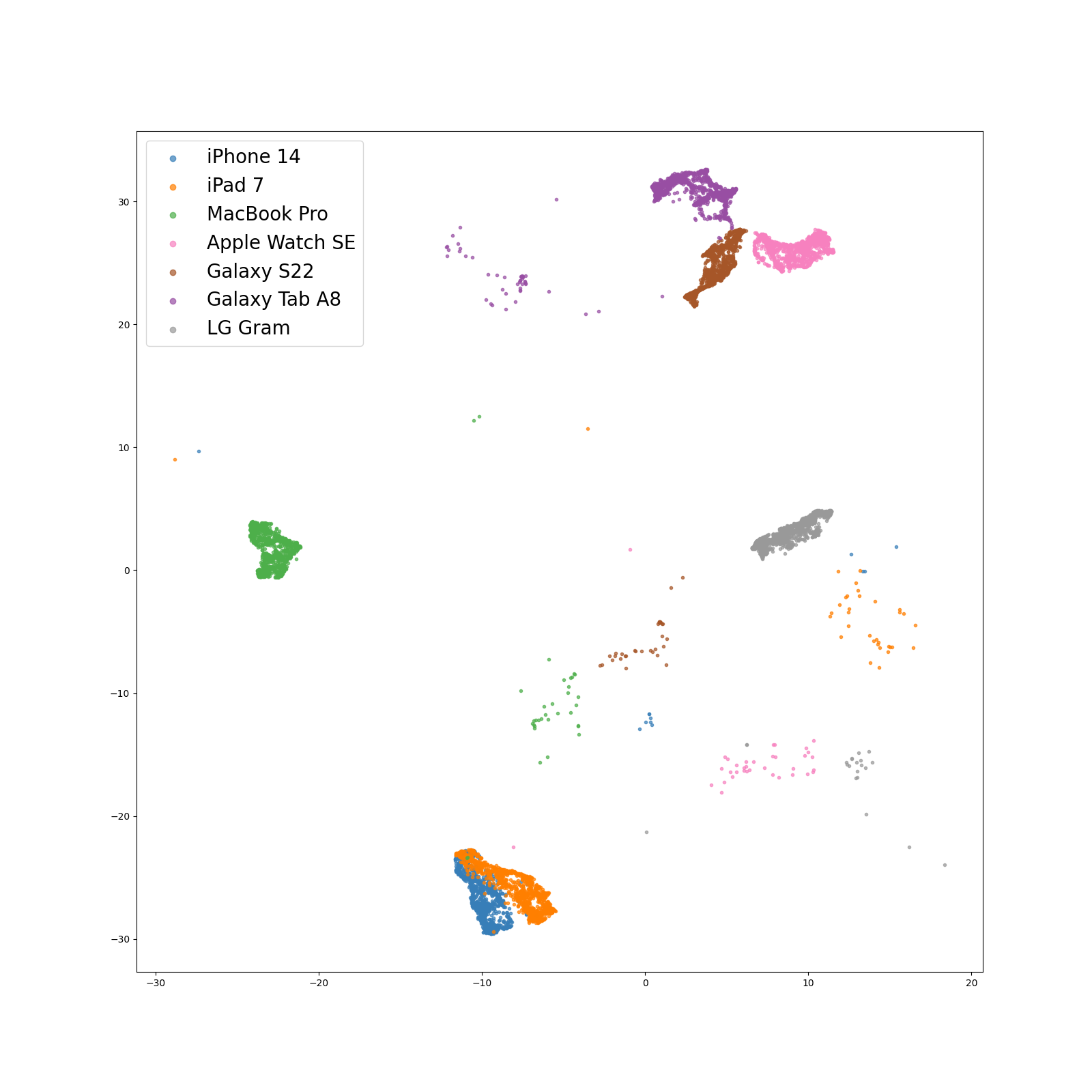
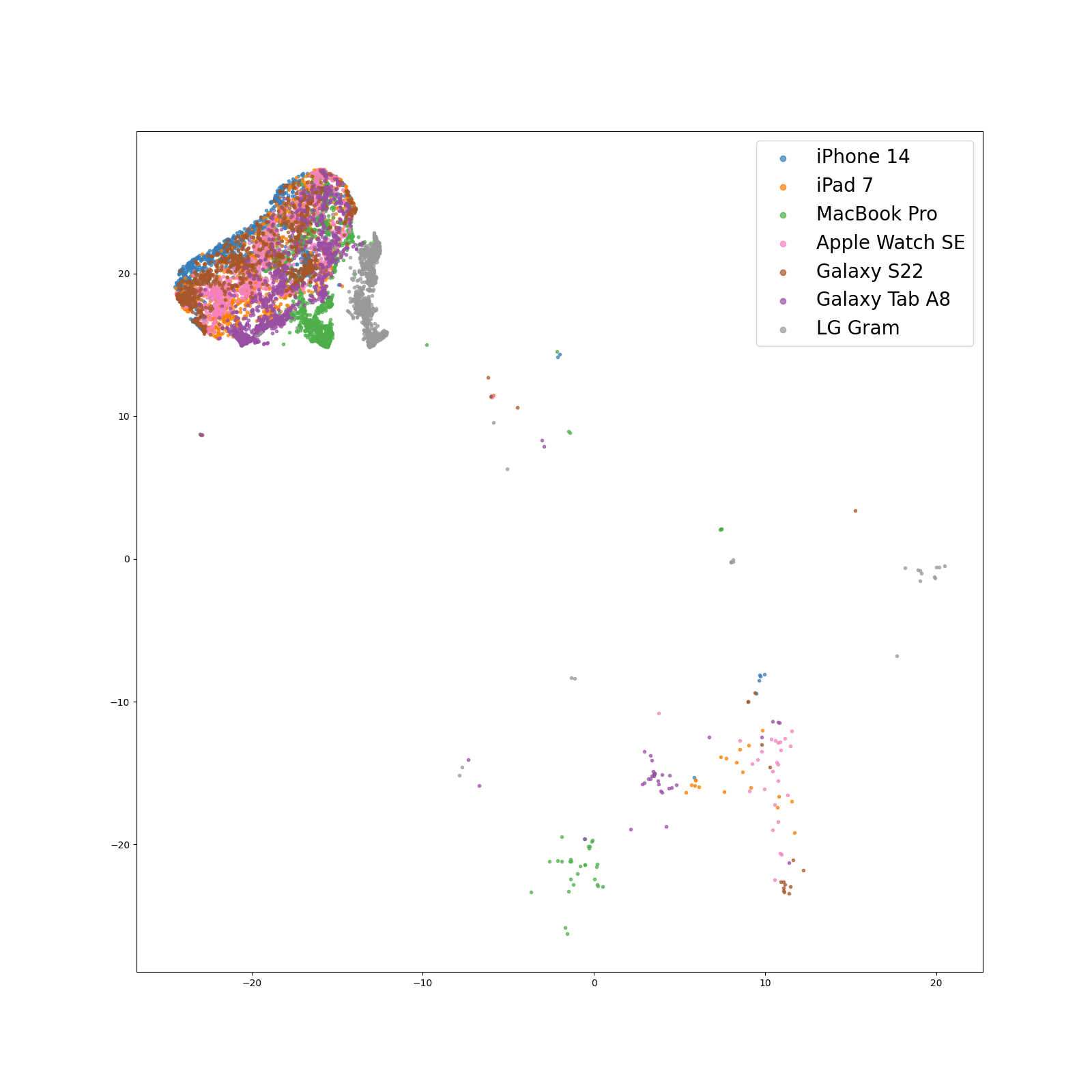
Among the more specialized recent approaches, Freq-MixStyle emerged as the most effective, achieving an average F1 score of 85.5% and demonstrating consistent performance with a narrow 3.8% confidence interval. However, our Microphone Conversion technique, MC-200-Gen, trained for 200 epochs, outshone these methods with an impressive average F1 score of 90.7% and minimal variability (3.5%). In scenarios requiring adaptation, SEC models employing adaptation strategies generally outperformed MC-200-Adapt (p=0.5) on 4 out of 6 target devices, showing a 1.3% gain in overall performance. Remarkably, they nearly matched the ‘Real’ performance metric when trained on a diverse set of devices.
Our findings underscore the effectiveness of our Microphone Conversion approach, particularly its capability to enhance both generalization and adaptability of SEC systems. The promising results also suggest the potential for further optimization with extended training durations, paving the way for more robust and reliable SEC systems in the face of device variability.
Implications and Impact of Our Findings
In addressing the challenge of device variability in sound event classification (SEC) systems, our study has made significant strides with far-reaching implications. The development of a specialized sound event dataset, recorded across a variety of real-world devices in an anechoic chamber, marks a substantial advancement in the field. This dataset not only provides a more realistic and robust basis for training and testing SEC systems but also sets a new standard for future research in this area.
Our introduction of the Microphone Conversion method has been a game-changer in improving the performance of SEC systems. By significantly outperforming recent approaches in both generalization and adaptation tasks, this method showcases the potential of machine learning techniques in overcoming complex challenges in audio signal processing. The ability of our method to adapt to various recording devices enhances the versatility and reliability of SEC systems, paving the way for their broader application in diverse real-world scenarios. This includes improved accuracy in voice-activated devices, enhanced sound recognition in security systems, and more effective environmental sound analysis in smart city infrastructure.
However, our findings also highlight an area for future exploration. The CycleGAN component of our solution, while effective, is currently limited by its assumption of a one-to-one domain mapping. This necessitates separate models for each domain pair, which can be resource-intensive and less scalable. Exploring the integration of impulse response characteristics with CycleGAN presents an exciting opportunity for more versatile domain mapping. Such advancements could lead to even more sophisticated and adaptable SEC systems, capable of handling a wider array of acoustic environments with fewer model constraints.
In summary, our findings not only demonstrate a significant improvement in handling device variability in SEC but also open up new avenues for research and development. The implications of this work extend beyond academic research, suggesting practical applications in various industries where sound recognition plays a crucial role. As technology continues to evolve, the integration of our methods could lead to more intelligent, adaptable, and efficient sound recognition systems, fundamentally transforming how we interact with and interpret the sounds in our environment.
Citation
Myeonghoon Ryu*, Hongseok Oh*, Han Park, Suji Lee. “Microphone Conversion: Mitigating Device Variability in Sound Event Classification”, in 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
@inproceedings{icassp2024mic_conversion,
author = {Myeonghoon Ryu and Hongseok Oh and Han Park and Suji Lee},
title = {Microphone Conversion: Mitigating Device Variability in Sound Event Classification},
booktitle = {2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year = {2024},
organization={IEEE}
}